msr-paper-2018
Who’s this? Developer Identification Using IDE Event Data
Study overview
In this study looked at the possibility of matching a programmers actions within an IDE during a programming session to a programmer. The motivation of classifying a session to a programmer came from the belief that if we could accurately classify a programming session to a programmer then a session must be characteristic of a programmers IDE behavior. If this is the case you could then use session behaviour to for example recommend IDE tools to programmers based on tools programmers with similar session characteristics use. For this study we used the KaVE data set which was created using the FeedBaG++ tool to capture developers’ behaviour within an IDE and transform them into Enriched Event Streams. The data set contained events from 85 developers from a variety of backgrounds (industry, research, students and hobbyists) and in total contains 11M events. A session contains multiple events from a specific developer that occurred in a single day. An event is added to an event stream when a developer interacts with an IDE, for example by clicking the build button. In order to classify a session to a programmer we considered two types of classifiers: Support Vector Machines (SVM) and k-Nearest Neighbour. We additionally experimented with applying term frequency - inverse document frequency (tf-idf) as a preprocessing step to the input data.
We looked to answer the following three questions: RQ1: A Comparison of SVN to k-NN. Which classifier offers the best performance on identifying developers based on their IDE events? RQ2: Minimum events per session. How many events per session give the highest classification accuracy? RQ3: Minimum sessions per developer. How many sessions per developer give the highest classification accuracy?
Before we could train the classifiers a number of pre-processing steps were required. The initial stage, as depicted in fig 1, consisted of splitting each developer’s event streams into a set of event streams per session and labelling each session’s event streams with a unique developer ID to identify the developer whom the session belonged to. For each session, a count was carried out to sum the number of occurrences of each event type within that session. We created three levels of Event Granularity (EG). These three levels of EG were used for representing the types of events being counted. The coarse-grained EG (CEG) consists of 15 event types (activity, command, completion, build, debugger, document, edit, find, IDE state, solution, window, version control, navigation, system, and test run) used in the EES as shown in num (error, info and user profile events were not included because the error and info events do not occur in the data set and the user profile event was not considered an IDE event). The medium-grained EG (MEG) further divided the CEGs into smaller sub groups of events. For example, a build event was split into: build, build all, rebuild all and unknown. This resulted in 49 different MEG types. Lastly, the fine-grained level EG (FEG) made use of the 49 MEG types and also subdivided the command event into another 42 new types of events, giving 91 FEG types in total. This was implemented using string matching on the command id. A full overview of which events make up each granularity can be seen at the bottom of this page. Each session was represented by a concatenation of the three vectors, one for each of the three levels of granularity, as shown in fig 2.
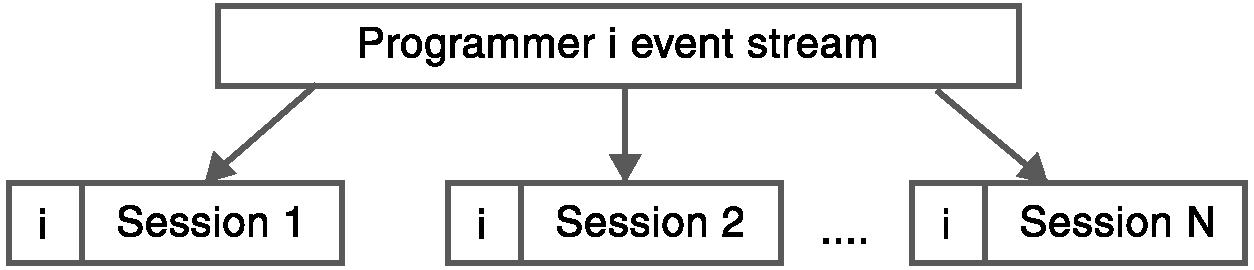
Fig 1: Initial stage in splitting developer event stream
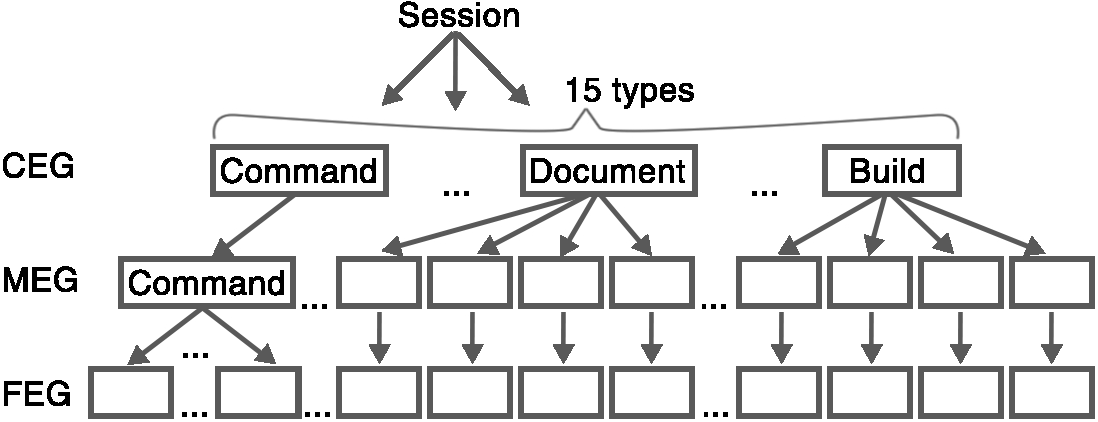
Fig 2: Event granularities
Besides the three granularity levels, we evaluated two types of input vector values to the classifiers in this study: raw event counts and tf–idf. For each session, we first created three session vectors (CEG, MEG, and FEG) with raw event counts and derived three vectors of tf–idf from them. This resulted in 6 vectors for each session CEG, CEG with tf–idf (CEGT), MEG, MEG with tf–idf (MEGT), FEG and FEG with tf–idf (FEGT) as shown in fig 3.
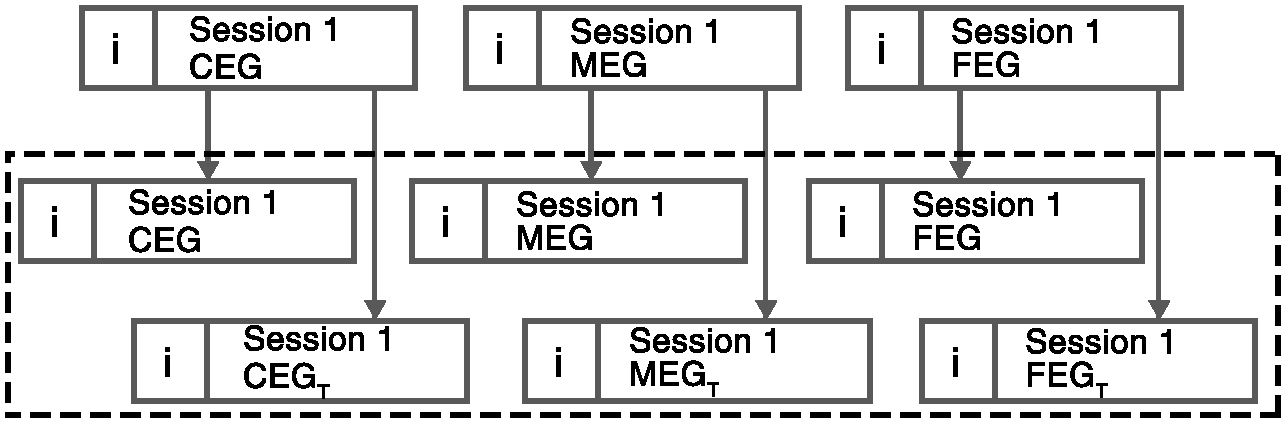
Fig 3: The six vectors representing a session
Each session vector was then grouped together with all other session vectors of the same EG, and grouped based on whether tf–idf had been applied. For example, all session vectors which had been generated using CEGT were grouped together into one set. These session groups were used as the training data for classifiers.
The classification uses the preprocessed vector data. For each developer, we randomly selected a fixed number of sessions from all their sessions. Then, the selected sessions were split into training and testing sets. The training set utilised 80\% of the original data, while the remaining 20\% was assigned as the testing set. The training set was used with k-fold cross validation to tune the parameters for the two classifiers. In the case of k-NN, we tuned the threshold for distance measure and the number n for neighbours. In the case of an SVM, the training data is used for selecting the kernel and tuning the penalty of the error term, which resulted in a linear kernel to be selected. With the parameter selection and tuning, we trained the classifiers using the training data set, then the trained classifiers were used to predict the most likely developer for each session in the testing data set. These predictions were then compared to the true developer of the session and the accuracy was measured.
Key results
RQ1: A Comparison of SVN to k-NN
This RQ compares the SVM classification performance compared to k-NN for six different event granularities and vector values: CEG, CEGT, MEG, MEGT, FEG, FEGT data sets. We filtered the 6 data sets to only include rich sessions with at least 500 events (42\% of all the sessions) with the aim of removing sessions that contained too few events to characterise a developer. This assumption was then explored in RQ2. From this data, developers with at least 10 sessions were selected (40 out of 82 developers), and then for each developer 10 sessions were randomly selected so that each developer has the same number of sessions in order to avoid an evaluation bias. This resulted in 40 developers with a total of 400 sessions. Each classifier was trained using 80% of the sessions, and the accuracy was measured by classifying the remaining 20% of sessions. The results are shown in fig 4. The highest accuracy of 0.52 was achieved using the SVM classifier on FEG. The lowest accuracy (close to zero) occurred using the SVM on all data sets with tf–idf. In contrast, the k-NN classifier performed more accurately on the data sets with tf–idf, i.e.CEGT, MEGT, FEGT. The highest accuracy achieved using the k-NN classifier was 0.475 on FEGT data set. Both classifiers performed best, with or without tf–idf, on the FEGs, followed by MEGs, and CEGs respectively.
To answer RQ1, the findings indicate that an SVM with a linear kernel is a more appropriate classifier for IDE event data than k-NN. It was found to be detrimental to apply tf–idf to session vectors before training the SVM.
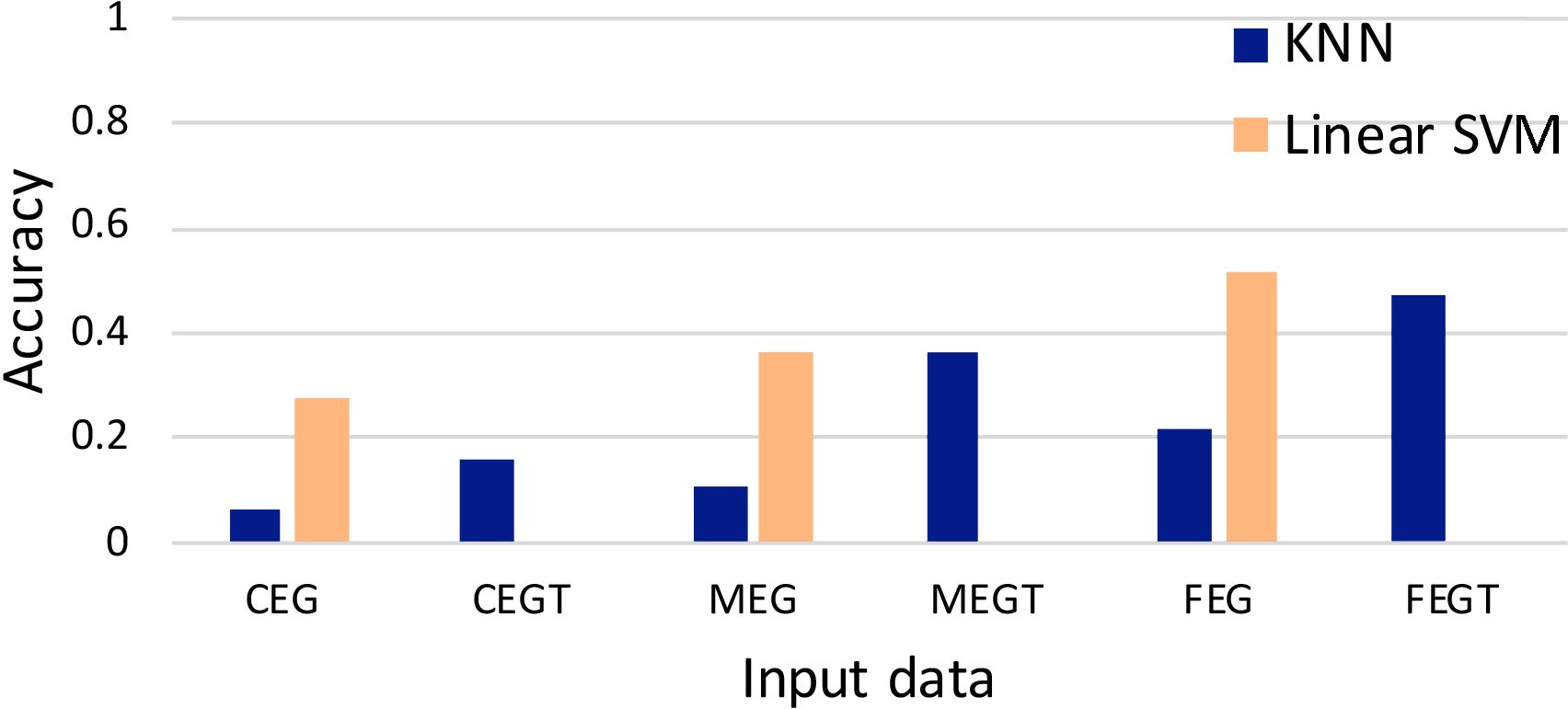
Fig 4: Classification performance on six input data types
RQ2: Minimum events per session
Five thresholds were considered starting with zero events (all sessions included) with an increasing step of 500 up to a threshold of 2,000 events. This was done using FEG data to train an SVM classifier on 10 sessions for each developer. Similar to RQ1, 10 sessions for each developer were randomly selected from all of the developer’s sessions. To control the number of developers across the five threshold values, we selected the 23 developers that had at least 10 sessions with at least 2,000 events. The results of the changing thresholds on the accuracy of the classifier can be seen in fig 5. The highest accuracy of 0.69 was achieved when the threshold was set to 1,500 followed by 0.63 using a threshold of 2,000 and 0.62 using a threshold of 500. The increased accuracy for the threshold of 500 in comparison to the findings of RQ1 is due to having fewer developers to classify a session to and thus making the classification task simpler.
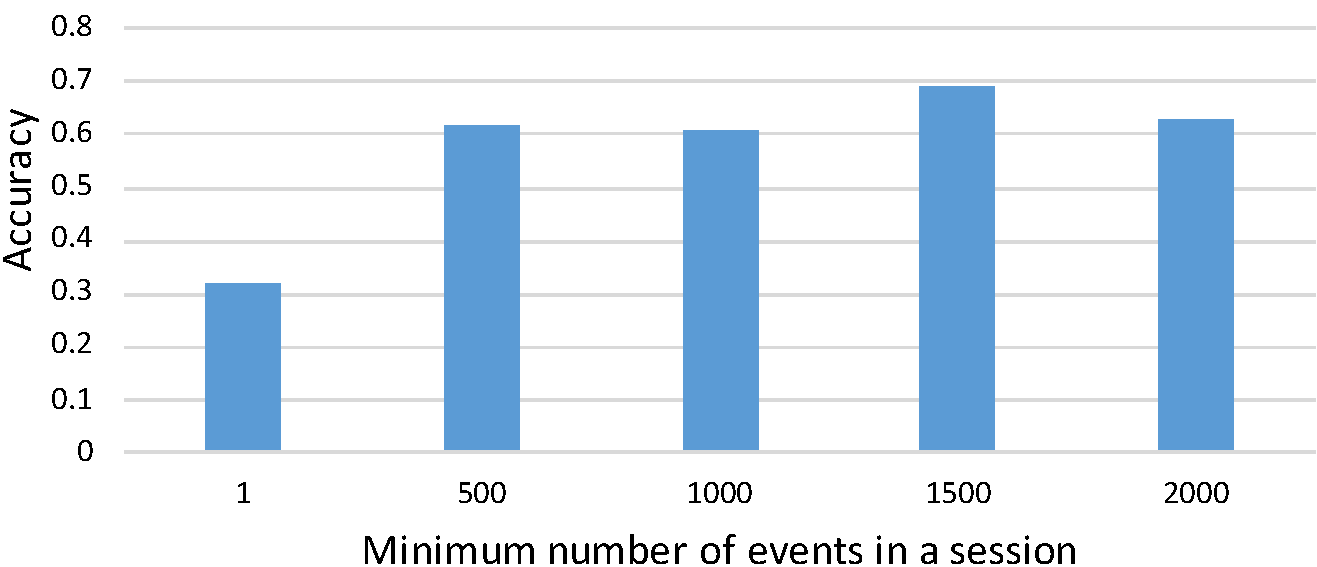
Fig 5: Minimum number of events vs. accuracy
RQ3: Minimum sessions per developer
The chosen values for the number of sessions included 5, 10, 15, 20 and 25. Again, we tested using an SVM classifier with FEG data, with sessions of at least 500 events. We obtained 20 developers that had at least 25 sessions to control the number of developers. The classification accuracy can be seen in fig 6. The highest accuracy of 0.71 was achieved when the threshold was set to 20 sessions per developer, followed by 25 and 15 sessions.
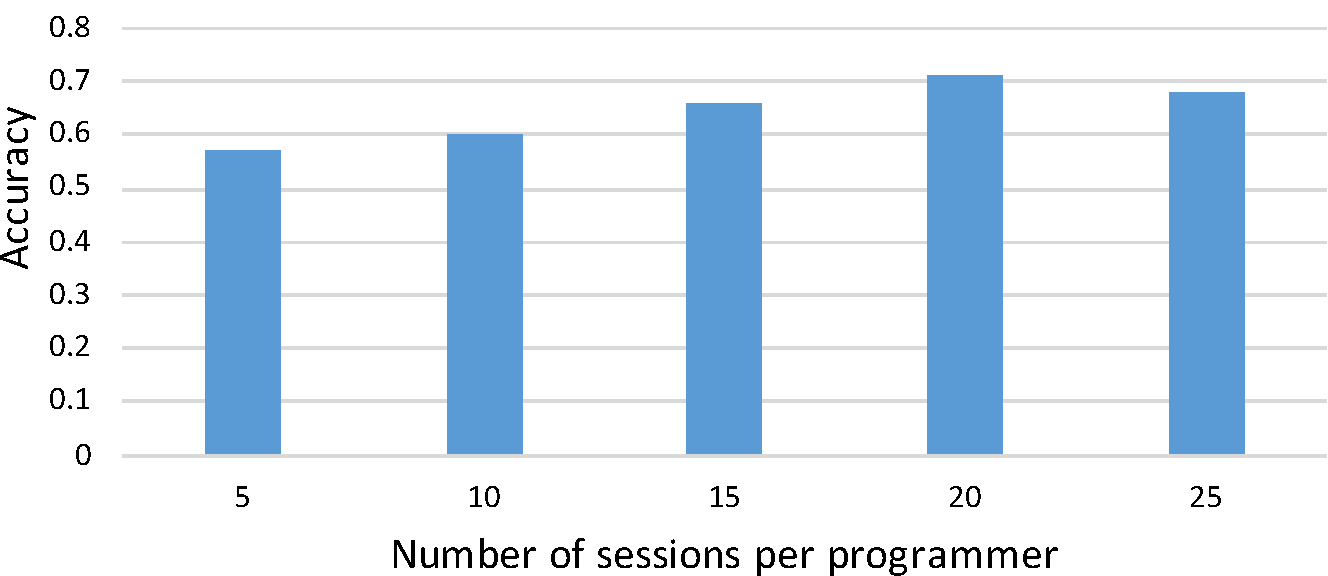
Fig 6: Number of sessions vs. accuracy
Event types in each granularity
| CEG | MEG | FEG |
|---|---|---|
| activity | activity | activity |
| completion | completion | completion |
| build | (build) rebuild all | (build) rebuild all |
| (build) clean | (build) clean | |
| (build) build | (build) build | |
| (build) unknown | (build) unknown | |
| debugger | (debugger) design | (debugger) design |
| (debugger) break | (debugger) break | |
| (debugger) exception not handled | (debugger) exception not handled | |
| (debugger) exception thrown | (debugger) exception thrown | |
| (debugger) run | (debugger) run | |
| document | (document) close | (document) close |
| (document) opened | (document) opened | |
| (document) saved | (document) saved | |
| edit | (edit) less than 5 changes | (edit) less than 5 changes |
| (edit) 5 to 9 changes | (edit) 5 to 9 changes | |
| (edit) 10+ changes | (edit) 10+ changes | |
| find | (find) canceled | (find) canceled |
| (find) complete | (find) complete | |
| IDE state | (state) shut down | (state) shut down |
| (state) start up | (state) start up | |
| solution | (solution) add project | (solution) add project |
| (solution) add project item | (solution) add project item | |
| (solution) add solution item | (solution) add solution item | |
| (solution) close solution | (solution) close solution | |
| (solution) open solution | (solution) open solution | |
| (solution) remove project | (solution) remove project | |
| (solution) remove solution item | (solution) remove solution item | |
| (solution) rename project | (solution) rename project | |
| (solution) rename project item | (solution) rename project item | |
| (solution) rename solution | (solution) rename solution | |
| window | (window) activate | (window) activate |
| (window) close | (window) close | |
| (window) create | (window) create | |
| (window) deactivate | (window) deactivate | |
| (window) move | (window) move | |
| version control | version control | version control |
| navigation | (navigation) click | (navigation) click |
| (navigation) ctrl click | (navigation) ctrl click | |
| (navigation) keyboard | (navigation) keyboard | |
| system | (system) lock | (system) lock |
| (system) remote connect | (system) remote connect | |
| (system) remote disconnect | (system) remote disconnect | |
| (system) resume | (system) resume | |
| (system) suspend | (system) suspend | |
| (system) unlock | (system) unlock | |
| test run | test run | test run |
| command | command | (command) team |
| (command) debug | ||
| (command) help | ||
| (command) window | ||
| (command) tools | ||
| (command) resources | ||
| (command) file | ||
| (command) save | ||
| (command) view | ||
| (command) unit test | ||
| (command) edit | ||
| (command) close | ||
| (command) build | ||
| (command) completion | ||
| (command) bulb action | ||
| (command) project | ||
| (command) other context menues | ||
| (command) find usages | ||
| (command) test explorer | ||
| (command) unit test session | ||
| (command) bookmarks | ||
| (command) generate | ||
| (command) choose language | ||
| (command) continuous testing | ||
| (command) solution explorer | ||
| (command) nuget | ||
| (command) visual svn | ||
| (command) viemu | ||
| (command) refactorings | ||
| (command) kave | ||
| (command) obs | ||
| (command) sql | ||
| (command) code maid | ||
| (command) text control | ||
| (command) type hierarchy | ||
| (command) ncrunch | ||
| (command) mercurial | ||
| (command) tree model browser | ||
| (command) super charger | ||
| (command) architecture designer | ||
| (command) architecture context menues | ||
| (command) jet brains | ||
| (command) unknown |